Everything is Linear Up High, Everything is Curved Down Low: Distributed Representations and the Brain’s Geometry

🤖 Cover image generated by AI.
Blog 2 of a series on Geometry, Topology, and the Future of Machine Learning Representation
“The brain does not store the world. It stores the algebra of the world.”
Picking Up Where We Left Off
In the first blog of this series, we climbed a ladder of mathematical spaces — from bare topological spaces, through metric and inner product spaces, up to Hilbert spaces of signals — and argued that the dominant paradigm in representation learning is stuck at one rung of that ladder. Current LLMs represent meaning as static points in a finite-dimensional inner product space: real-valued vectors with amplitude but no phase, location but no dynamics.
The natural question that follows is: what should a better representation look like, and does anything in nature already do it?
The answer to the second part is unambiguous: yes, the brain does it, and it has been doing it for hundreds of millions of years. The brain’s solution to representation is neither a static vector nor a simple function. It is a distributed algebraic structure — patterns spread across enormous populations of neurons, composed and decomposed by operations that look a lot like the mathematics of signal processing and symbolic algebra.
This blog develops that idea in three acts. First, we ask what geometry high-dimensional data actually has — this is the Manifold Hypothesis, and its implications are stranger than they might seem. Second, we look at how the brain navigates the fundamental tension between generalisation and discrimination, and why it does so with a specific computational circuit that machine learning is only beginning to rediscover. Third, we introduce Vector Symbolic Architectures (VSAs) — a family of frameworks for encoding structured, compositional meaning into distributed representations — and argue that they, more than any other existing formalism, point toward what multimodal generalisation actually requires.
Part I: The Geometry of High-Dimensional Data
Cover’s Theorem and the Linearity of High Dimensions
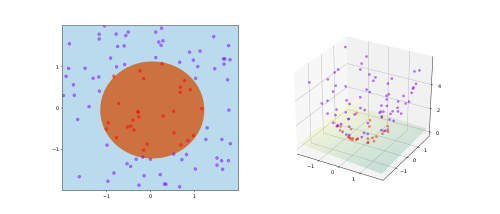
There is a theorem from 1965 that is well-known in the theory of support vector machines but deserves to be much more central to how machine learning practitioners think about representation. Cover’s theorem [1] states:
A pattern classification problem cast into a sufficiently high-dimensional space is more likely to be linearly separable than in a lower-dimensional one.

Image source: reference image
Read that carefully. It is not saying that high-dimensional spaces are easier to work in for some vague reason. It is making a precise geometric claim: if you take a classification problem that is not linearly separable in low dimensions, and you map the data into a sufficiently high-dimensional space (with a nonlinear map), a hyperplane will almost surely suffice. This is the theoretical foundation of kernel methods — the kernel trick implicitly embeds data into a very high-dimensional (often infinite-dimensional) feature space where linear separation becomes possible [2].
The Johnson-Lindenstrauss lemma [3] makes an even stronger statement about what happens in high dimensions: a random projection of \(n\) points from \(\mathbb{R}^d\) into \(\mathbb{R}^k\) (with \(k = O(\log n / \epsilon^2)\)) preserves all pairwise distances up to a factor of \((1 \pm \epsilon)\). This is the core theme behind all the dimensionality reduction techniques. Geometric structure — the shape of the data — survives random projection into high dimensions. You do not need to carefully engineer the high-dimensional space; randomness preserves geometry almost for free.
Together, these results suggest something philosophically interesting: high-dimensional spaces are “more linear.” Complex, curved, tangled relationships in low dimensions tend to become linearly separable when you go up. The nonlinearity is not an intrinsic property of the data — it is a property of the low-dimensional projection you happen to be looking at.
Consider a unit hypercube. The distance from the center to a corner in \(d\) dimensions is \(\frac{\sqrt{d}}{2}\). In 3D, that distance is roughly 0.86.In 1,000D, that distance is approximately 15.8.The corners are “stretching” away into the distance. Simultaneously, the volume of a hypersphere inscribed in that cube shrinks to almost zero relative to the cube. By the time you reach 10 dimensions, the sphere occupies less than 0.25% of the cube’s volume. A reference YouTube video for explanation
The implication is profound: In high dimensions, almost all the volume of a cube is concentrated in its corners. If you were to drop “data points” randomly into this space, they would be so far apart that the concept of a “nearest neighbor” becomes mathematically meaningless. The space is a vast, freezing void of “corners.”
The Manifold Hypothesis: Where the Data Actually Lives
In high-dimensional space, the “Curse of Dimensionality” means that the ambient space is unimaginably vast and mostly empty. If data were distributed uniformly, machine learning would be impossible because we could never collect enough samples to “fill” that space. The Manifold Hypothesis [4] is the observation that nature is “lazy”—it doesn’t use all those corners; it restricts itself to a tiny, structured, curved subset. Images, sounds, and language samples occupy a tiny, curved, low-dimensional manifold embedded within the ambient high-dimensional space. The effective dimensionality of natural images — the number of dimensions you need to account for most of the variance — is far smaller than the pixel count.
This is not just an empirical observation; it follows from the structure of the world. Images of faces are constrained by the geometry of faces: two eyes, a nose, a mouth, all varying continuously with pose, expression, and lighting. The space of valid faces is a manifold parameterised by a handful of continuous variables, embedded in \(\mathbb{R}^{3 \times H \times W}\).
Manifolds have a key geometric property: they are locally Euclidean but globally curved. A small enough neighbourhood of any point on a smooth manifold looks flat — like a patch of \(\mathbb{R}^k\) for some small \(k\). But the global structure can be highly curved, twisted, and topologically complex. A Swiss roll is two-dimensional globally but looks one-dimensional locally if you zoom in far enough along one direction.

Image source: reference image
This has a direct implication for representation learning:
- In the high-dimensional ambient space: data is sparse, geometry is preserved by random projections, and linear separability is achievable. This is where expansion is useful.
- In the low-dimensional intrinsic space: the manifold has curvature, and a linear map from the ambient space to the intrinsic space will destroy that curvature. You need a nonlinear map — one that “unfolds” the manifold onto a flat coordinate system.
The nonlinearities in deep neural networks are not arbitrary engineering choices. They are the mathematical necessities of mapping a curved low-dimensional manifold onto a flat representational space. A network that is purely linear can only learn linear projections; it cannot unfold a Swiss roll. Rectified linear units, sigmoid functions, and their cousins are the mechanism by which a network “flattens” manifold curvature.
What Current Models Do Well — and What They Miss (Unfolding vs. Expanding)
Modern deep learning systems can be understood as powerful manifold-learning machines. Through successive nonlinear layers, they progressively “unfold” the data manifold. Since small regions are approximately linear, each layer applies local linear transformations that gradually flatten the global structure; it has been confirmed empirically and to some extent theoretically [5, 6].
Large language models extend this idea further. In Transformers, representations evolve layer by layer: a token starts with a lexical embedding and is iteratively refined toward a context-aware meaning. Attention mechanisms guide these updates, determining which parts of the representation space are relevant at each step.
This framework explains much of their success.
However, there is an important limitation.
Manifold learning is fundamentally a compression strategy. It focuses on discovering low-dimensional, invariant structure—capturing what generalizes across variations. This is extremely powerful, but it emphasizes abstraction over distinction.
What it does not naturally provide is the complementary capability: high-dimensional expansion for precise discrimination and compositional structure.
This is where Cover’s Theorem becomes relevant again. It tells us that even if the data manifold remains complex and entangled, projecting it into a sufficiently high-dimensional space makes different points sparse and, therefore, easier to separate linearly. In other words, expansion enables fine-grained discrimination.
So we are left with two complementary needs:
- Unfolding (via nonlinear transformations): to capture structure and enable generalization
- Expanding (via high-dimensional representations): to preserve separability and precision
Current models are exceptionally good at the first. They compress, abstract, and generalize. But relying on compression alone risks losing the fine distinctions needed for precise reasoning and compositionality.
To build systems that both generalize and discriminate effectively, we need a balance between these two strategies.
This naturally raises a deeper question: how does the brain achieve this balance?
Part II: The Brain’s Circuit — Expansion, Compression, and the Loop Between Them

Image source: reference image
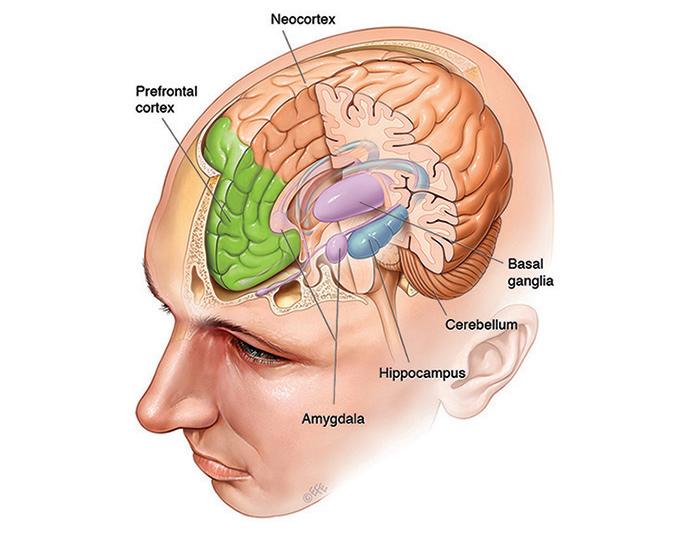
The Fundamental Circuit
The brain’s core computational strategy, implemented at every scale from individual cortical columns to large-scale systems, is a two-phase cycle [7]:
- Expand inputs into a very high-dimensional, sparse representation — make similar things distinguishable (pattern separation)
- Compress that representation back down to a low-dimensional manifold — make variable things consistent (pattern completion and generalisation)
This is not a metaphor or an analogy. It is the literal wiring diagram of the brain’s major circuits. Understanding why the brain uses both phases — and why neither alone is sufficient — is the key to understanding what is missing from current ML representations.
The Cerebellum: Expansion as Precision
The cerebellum contains roughly 80% of the brain’s neurons, the vast majority of which are granule cells [8]. Its input arrives via mossy fibres as a relatively low-dimensional signal — motor states, sensory feedback, contextual cues. The cerebellum immediately explodes this into an enormous population of granule cell activations: the input is mapped into a space of order \(10^{10}\) or more dimensions, with extremely sparse activation (only a tiny fraction of granule cells active at any moment).
What does this buy? Pattern separation. Two motor commands that are nearly identical in low-dimensional space — “move my arm 10 degrees” and “move my arm 11 degrees” — will, after expansion into the granule cell layer, activate largely non-overlapping populations. They become, in Cover’s theorem’s language, linearly separable. The Purkinje cells that read out from the granule layer can learn to discriminate them with a simple linear threshold.
This is expansion coding: the cerebellum is implementing, in neural hardware, exactly what kernel methods implement mathematically. It is mapping inputs into a space where linear readout suffices, using sparse random-like projections that preserve the geometry of the input manifold while making fine distinctions tractable.
The price is that nothing generalises at the granule cell level. Every new context activates a new, essentially orthogonal pattern. The cerebellum is not in the business of abstraction; it is in the business of precision.
The Neocortex: Compression as Generalisation
The neocortex operates as a hierarchical compression engine [9]. The canonical example is the ventral visual stream — the pathway from primary visual cortex (V1) to inferotemporal cortex (IT) that underlies object recognition.
Raw retinal input is high-dimensional: millions of photoreceptors encoding pixel-level light intensities. As signals propagate up the hierarchy, successive areas discard information that is irrelevant to object identity — exact pixel positions, local contrast, low-level edge orientations — and preserve information that is invariant across viewing conditions: object shape, part configuration, surface texture. By the time the representation reaches IT cortex, a face is represented by a low-dimensional pattern that fires consistently regardless of whether the face is seen from the left, the right, in bright light, or in shadow [10].
This is manifold compression: the neocortex is learning the intrinsic low-dimensional manifold of object identity, stripping away the high-dimensional variation that is due to viewing conditions rather than object properties. The result is a representation that generalises beautifully — you recognise a friend’s face under any lighting condition — but that cannot distinguish fine-grained details when they are critical.
The Hippocampus: Both at Once
The hippocampus is where the two strategies meet, and its internal architecture is a microcosm of the full expansion-compression story [11].
The dentate gyrus (DG) performs extreme expansion: approximately \(10^6\) granule cells receive input from roughly \(10^7\) entorhinal cortex neurons, with very sparse coding (~5% active). Each episode, each memory, is mapped to a largely orthogonal high-dimensional pattern. This is pattern separation at its most extreme — the reason you can distinguish this morning’s breakfast from yesterday’s, despite them sharing almost all features.
CA3 uses dense recurrent connectivity to perform pattern completion: given a partial or degraded input, it reconstructs the full stored pattern. This is the manifold-like operation — it maps the noisy partial input onto the nearest attractor in a learned landscape of stored memories.
CA1 then compresses back to a compact index, integrating the CA3 completion with direct entorhinal input to form a final contextual representation.
The hippocampal circuit is, in essence, a learned compressor-expander: it stores experiences by first separating them (DG), enabling recall from partial cues (CA3), and then indexing them efficiently (CA1). The same circuit that enables you to recall yesterday’s lunch in full detail from a single smell is also what enables you to generalise “lunch” as a concept across all instances.
Why Machine Learning Needs Both
Current deep learning models are, structurally, predominantly neocortical: they are compression engines. A ResNet, a Vision Transformer, a large language model — all of these are hierarchical compression machines that learn to map high-dimensional input onto low-dimensional manifolds. They generalise admirably. They fail at precise discrimination when fine-grained distinctions matter, and they struggle to bind features into structured compositional wholes.
The cerebellar strategy — high-dimensional sparse expansion for discriminability — appears in machine learning mainly as a historical artefact (the kernel trick, radial basis function networks) or as a computational trick (random feature methods, locality-sensitive hashing). It has not been deeply integrated into the representational philosophy of modern architectures.
What is almost entirely absent is the loop: the closed circuit between expansion and compression, the feedback that allows the brain to use discrimination to sharpen generalisation and generalisation to guide discrimination. The thalamus, basal ganglia, and dopaminergic modulation systems implement this loop biologically. Machine learning has gradient descent, which is a crude approximation — but it operates on the full network simultaneously rather than as a structured interplay between specialised subsystems.
Part III: Vector Symbolic Architectures — Algebra in a High-Dimensional Space
The Core Idea
Vector Symbolic Architectures (VSAs) [12, 13] are a family of frameworks that address a different gap: not the expansion-compression trade-off, but the question of compositional structure. How do you represent the fact that “the red ball is to the left of the blue cube” in a way that supports inference, binding, and decomposition?
The standard neural network answer is: learn it from data, hope the structure is implicit in the weights. The VSA answer is: use mathematics. Encode all atomic concepts as random high-dimensional vectors, and use algebraic operations — binding, superposition, permutation — to compose them into structured representations.
The key insight, which is the bridge between Cover’s theorem and distributed representation, is this: in a sufficiently high-dimensional space, random vectors are approximately orthogonal to each other. If you draw two random unit vectors in \(\mathbb{R}^d\), their expected inner product is 0, with standard deviation \(1/\sqrt{d}\). In \(d = 10000\), the expected angle between two random vectors is within \(0.6°\) of 90°. This means that a high-dimensional space can hold an exponentially large number of “symbols” — random vectors — that are all approximately orthogonal, and therefore approximately non-interfering.
VSAs exploit this property to build a kind of distributed algebra: you can add, multiply, and permute high-dimensional vectors to encode structured information, and the result is a single high-dimensional vector — no bigger than the originals — that can be queried to recover the components. A reference YouTube video for explanation
The Major VSA Families
Holographic Reduced Representations (HRR) [12]: Real-valued vectors of fixed dimension \(d\). Binding is circular convolution:
\[\mathbf{a} \circledast \mathbf{b} = \text{IFFT}(\text{FFT}(\mathbf{a}) \cdot \text{FFT}(\mathbf{b}))\]
Superposition is vector addition. Unbinding is approximate (circular correlation with the approximate inverse). HRRs can represent nested structures — “(colour:red) + (shape:sphere) + (position:left)” as a single vector — and partially recover components via querying. The connection to the Fourier domain is not incidental: circular convolution is element-wise multiplication in frequency space, making HRRs a natural signal-processing object.
Binary Spatter Codes (BSC) [14]: Binary vectors \(\{0,1\}^d\). Binding is XOR, superposition is majority vote. Extremely hardware-efficient — binding is a single bitwise operation — and well-suited to neuromorphic or edge computing. The binary constraint limits capacity and expressiveness compared to real or complex variants.
MAP-C (Multiply-Add-Permute, Complex) [15]: Phasor vectors on the unit circle in \(\mathbb{C}^d\) — each component has magnitude 1 and a phase \(\theta \in [0, 2\pi)\). Binding is element-wise complex multiplication (phase addition):
\[(\mathbf{a} \otimes \mathbf{b})_i = a_i \cdot b_i = e^{i(\theta_i^a + \theta_i^b)}\]
Superposition is vector summation. Crucially, unbinding is exact: the inverse of complex multiplication is conjugation, \((\mathbf{a} \otimes \mathbf{b}) \otimes \bar{\mathbf{a}} = \mathbf{b}\). MAP-C has the highest known capacity for clean symbolic algebra in VSAs and is currently state-of-the-art for lossless compositional structure.
Fourier HRR (FHRR) [16]: Equivalent to MAP-C but framed explicitly in terms of the Discrete Fourier Transform. Binding in FHRR is multiplication in the frequency domain — which is convolution in the time domain. This framing makes the connection to signal processing fully explicit: FHRR is HRR where the carrier is the Fourier basis, and binding corresponds to phase-shift convolution. This is why FHRR representations are particularly natural for encoding temporal or spectral structure.
Resonator Networks [17]: Not a VSA variant but a VSA algorithm. Given a product vector \(\mathbf{z} = \mathbf{a} \otimes \mathbf{b} \otimes \mathbf{c}\), how do you recover \(\mathbf{a}\), \(\mathbf{b}\), and \(\mathbf{c}\) without brute-force search? Resonator networks solve this via a recurrent attractor dynamic: start with noisy estimates of each factor, iteratively update each estimate using the others, and converge to the true factors. The name comes from the resonance-like dynamics — factors “lock in” when they become mutually consistent. This is analogous to phase-locking in neural oscillator networks.
Sparse Distributed Memory (SDM) [14]: Kanerva’s foundational framework, predating the formal VSA literature. A content-addressable memory over a very high-dimensional binary address space, where reading and writing are distributed across all addresses within a Hamming-distance threshold. SDM is closely related to the Hopfield network in its attractor dynamics, and to the hippocampal CA3 pattern completion system. It is not strictly a VSA but shares the philosophy of distributed, superposed representation.
Binding and Superposition as Neural Operations
The two core VSA operations have direct neural correlates:
Superposition (vector addition) corresponds to the summation of neural activity across populations. If the population code for concept A is a pattern of firing rates, and for concept B is another pattern, then the simultaneous activation of both produces the superposition. The brain routinely maintains superposed representations — this is the mechanism behind working memory, where multiple items are held simultaneously without being confused, via slight phase offsets or temporal multiplexing.
Binding (circular convolution or complex multiplication) corresponds to temporal synchronisation or oscillatory coupling. The binding problem in neuroscience [18] asks: when you see a red ball and a blue cube simultaneously, how does the brain keep “red” bound to “ball” and “blue” bound to “cube,” rather than mixing them into “red cube” and “blue ball”? The dominant hypothesis is that features of the same object oscillate at the same phase in the gamma band (~40 Hz), while features of different objects oscillate at different phases. Phase is the binding operator in the brain, just as complex multiplication is the binding operator in MAP-C and FHRR.
This parallel is deep and not accidental. FHRR/MAP-C, with its unit-circle phasors and phase-addition binding, is a direct mathematical model of the phase-coding hypothesis of neural binding. The fact that this gives the highest VSA capacity is not surprising: the brain has been optimising this architecture for hundreds of millions of years.
Part IV: Distributed Representations and Multimodal Generalisation
Why Point Representations Fail at Multimodality
The standard approach to multimodal learning is: train modality-specific encoders, project their outputs into a shared \(\mathbb{R}^d\), and train contrastive or generative objectives to align the resulting points [19]. A cat image and a spoken description of a cat should land near the same point. This works remarkably well within modalities and for cross-modal retrieval.
But it fails at genuine compositional multimodal reasoning — the kind of task that requires understanding the structure of a scene, not just its identity. “Is the object to the left of the red thing also blue?” requires binding spatial relations, object identities, and colour attributes into a structured representation that can be queried compositionally. A point in \(\mathbb{R}^d\) encodes none of that structure explicitly; it is a holistic summary that has thrown away the compositional information.
VSAs provide exactly the structure that is missing. Consider encoding a simple visual scene with two objects:
\[\mathbf{scene} = (\mathbf{colour\_red} \otimes \mathbf{shape\_ball} \otimes \mathbf{pos\_left}) + (\mathbf{colour\_blue} \otimes \mathbf{shape\_cube} \otimes \mathbf{pos\_right})\]
This is a single vector in \(\mathbb{R}^d\) (or \(\mathbb{C}^d\)). But it supports structured queries:
\[\mathbf{scene} \otimes \mathbf{pos\_left}^{-1} \approx \mathbf{colour\_red} \otimes \mathbf{shape\_ball}\]
You can ask “what is at the left position?” by binding with the inverse of the position vector and reading out the approximate match from a codebook. This is compositional inference, performed by algebraic operations on distributed representations — no symbolic reasoner required, no explicit graph traversal.
The Expansion-VSA Connection
Here the two threads of this blog meet. Cover’s theorem says that high-dimensional spaces make patterns linearly separable. VSAs say that high-dimensional spaces can hold exponentially many approximately orthogonal symbols. These are two expressions of the same underlying geometry.
The cerebellum’s expansion coding and VSA superposition are both exploiting the same high-dimensional geometry: the fact that random vectors in \(\mathbb{R}^d\) are approximately orthogonal, and that therefore you can pack many non-interfering patterns into the same space. The difference is:
- Cerebellum: the high-dimensional space is used for discrimination — to separate similar patterns so that fine-grained readout is possible. The structure is sparse and approximately random.
- VSA: the high-dimensional space is used for composition — to bind structured relationships into a single vector that can be algebraically decomposed. The structure is algebraically organised.
A full neural architecture that takes inspiration from both would: 1. Expand multimodal inputs into high-dimensional sparse representations for discrimination (cerebellar strategy) 2. Bind feature representations into structured compositional vectors using VSA operations (algebraic strategy) 3. Compress the composed representations onto a low-dimensional manifold for generalisation (neocortical strategy) 4. Close the loop with feedback that uses generalisation to guide expansion and discrimination to refine composition
This is not a hypothetical future architecture. All of these components exist, in some form, in the current ML literature. What is missing is their integration into a coherent representational framework.
What Else Is Out There
The VSA landscape is not the only set of distributed representation tools worth knowing. Several other formalisms address adjacent problems:
Tensor Networks (Matrix Product States, MERA) [20] come from quantum physics and represent high-order joint distributions as networks of low-rank tensor contractions. They are powerful for data with strong local structure — sequences, grids — and map naturally onto the structure of attention in Transformers. For signal data with spectral structure, tensor trains (TT-decompositions) can represent complex multi-dimensional tensors with far fewer parameters.
Geometric / Clifford Algebra [21] generalises complex numbers, quaternions, and exterior algebra into a single framework where vectors, bivectors, and multivectors compose via the geometric product. For data with intrinsic geometric structure — 3D rotations, electromagnetic fields, physical simulations — Clifford algebra representations are equivariant by construction. They are underexplored in ML relative to their mathematical power.
Scattering Transforms [22] are wavelet-based, non-learned feature extractors that are provably stable under small deformations of the input. They extract hierarchical frequency information without any learning, and are particularly well-suited to non-stationary signals (audio, EEG, seismic data). For signal modalities where stability matters more than reconstruction, scattering transforms provide a principled alternative to learned encoders.
Sparse Coding / Dictionary Learning [23] decomposes signals as sparse linear combinations of learned basis atoms. This is philosophically different from VSA — there is no symbolic binding — but it is among the best methods for raw signal representation, and its atoms can be interpreted as the elementary features that the model has learned to recognise.
The Picture That Emerges
Let me close with the picture that the two blogs in this series are collectively building.
High-dimensional spaces are, in a precise sense, more linear: Cover’s theorem and Johnson-Lindenstrauss tell us that classification problems become separable and geometric structure is preserved under random projection. The brain’s cerebellar expansion exploits this geometry for discrimination. VSAs exploit it for compositional algebra.
Low-dimensional spaces are curved: the Manifold Hypothesis tells us that real data occupies a low-dimensional manifold with intrinsic curvature, and representing that manifold in a flat coordinate system requires nonlinear maps. The neocortex’s hierarchical compression exploits this structure for generalisation. Modern deep learning is, largely, an implementation of this strategy.
The brain does both, in a specific circuit with feedback loops. Current ML does predominantly the second. The gap is felt most acutely in multimodal reasoning, where you need to generalise across modalities (neocortical compression) while maintaining compositional structure (VSA algebra) and fine-grained discriminability (cerebellar expansion).
The next step — for the field, and for this series — is to ask whether VSAs, signals, and manifold theory can be integrated into a single framework. In particular: can a VSA with complex phasor vectors, whose binding operation is phase multiplication and whose superposition is signal summation, be understood as a representation in a Hilbert function space? Can the resonator network’s attractor dynamics be related to the hippocampus’s pattern completion? Can the expansion-compression loop be implemented differentiably?
These are open questions. But the mathematical vocabulary to ask them precisely now exists.
References
[1] Cover, T. M. (1965). Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE Transactions on Electronic Computers, EC-14(3), 326–334.
[2] Schölkopf, B., & Smola, A. J. (2002). Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press.
[3] Johnson, W. B., & Lindenstrauss, J. (1984). Extensions of Lipschitz mappings into a Hilbert space. Contemporary Mathematics, 26, 189–206.
[4] Fefferman, C., Mitter, S., & Narayanan, H. (2016). Testing the manifold hypothesis. Journal of the American Mathematical Society, 29(4), 983–1049.
[5] Brahma, P. P., Wu, D., & She, Y. (2016). Why deep learning works: A manifold disentanglement perspective. IEEE Transactions on Neural Networks and Learning Systems, 27(10), 1997–2008.
[6] Cabannes, V., Bottou, L., & Balestriero, R. (2023). Ssl back to basics: Addressing practical challenges in self-supervised learning. arXiv:2304.09438.
[7] Marr, D. (1969). A theory of cerebellar cortex. Journal of Physiology, 202(2), 437–470.
[8] Ito, M. (2008). Control of mental activities by internal models in the cerebellum. Nature Reviews Neuroscience, 9(4), 304–313.
[9] DiCarlo, J. J., Zoccolan, D., & Rust, N. C. (2012). How does the brain solve visual object recognition? Neuron, 73(3), 415–434.
[10] Tanaka, K. (1996). Inferotemporal cortex and object vision. Annual Review of Neuroscience, 19(1), 109–139.
[11] O’Reilly, R. C., & McClelland, J. L. (1994). Hippocampal conjunctive encoding, storage, and recall: avoiding a trade-off. Hippocampus, 4(6), 661–682.
[12] Plate, T. A. (1995). Holographic reduced representations. IEEE Transactions on Neural Networks, 6(3), 623–641.
[13] Kanerva, P. (2009). Hyperdimensional computing: An introduction to computing in distributed representation with high-dimensional random vectors. Cognitive Computation, 1(2), 139–159.
[14] Kanerva, P. (1988). Sparse Distributed Memory. MIT Press.
[15] Gayler, R. W. (2004). Vector symbolic architectures answer Jackendoff’s challenges for cognitive neuroscience. arXiv:cs/0412059.
[16] Plate, T. A. (2003). Holographic Reduced Representations: Distributed Representation for Cognitive Structures. CSLI Publications.
[17] Frady, E. P., Kent, S. J., Olshausen, B. A., & Sommer, F. T. (2020). Resonator networks, 1: An efficient solution for factoring high-dimensional, distributed representations of data structures. Neural Computation, 32(12), 2311–2331.
[18] Singer, W. (1999). Neuronal synchrony: A versatile code for the definition of relations? Neuron, 24(1), 49–65.
[19] Radford, A., et al. (2021). Learning transferable visual models from natural language supervision (CLIP). ICML 2021. https://arxiv.org/abs/2103.00020
[20] Stoudenmire, E. M., & Schwab, D. J. (2016). Supervised learning with tensor networks. NeurIPS 2016. https://arxiv.org/abs/1605.05775
[21] Ruhe, D., Gupta, J. K., de Boer, S., Brandstetter, J., & Forré, P. (2023). Clifford neural layers for PDE modeling. ICLR 2023. https://arxiv.org/abs/2209.04934
[22] Mallat, S. (2012). Group invariant scattering. Communications on Pure and Applied Mathematics, 65(10), 1331–1398.
[23] Olshausen, B. A., & Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381(6583), 607–609.
Blog 3 of this series will go deeper into Vector Symbolic Architectures as signal representations: why MAP-C/FHRR phasor vectors are natural elements of a Hilbert function space, how Resonator Networks relate to hippocampal pattern completion, and what a differentiable expansion-compression loop might look like as a neural architecture.
Author note: I have also used LLMs for restructuring and rephrasing, but the core ideas, technical direction, and learning are my own. The mathematical equations explaining each of the VSAs are also generated using LLMs.
Tags: distributed-representations vector-symbolic-architectures manifold-hypothesis neuroscience multimodal-learning hyperdimensional-computing compositional-reasoning machine-learning
posted by Dhruv @ April 11, 2026
0 Comments
![]()


{kind=link}
{kind=link}